Programming an Input Model
- cmcrter
- Nov 24, 2021
- 2 min read
For the city generation project, I need a way to add an example for the algorithm to use when programming the constraints (since that is a major part of the algorithm). If there's an example for the code to use to make adjacency rules and frequencies, it will be easier to see if the output breaks that. It's also a bonus to have when moving that aspect of the project over to user input one day, having a script already in place that can read a given grid.
For the Input model it will use the order of the children in the hierarchy, and height/width values in the inspector to create a grid relative to it. I've started with an extremely simple input model for testing, where all the tiles' values are really easy to see and check.
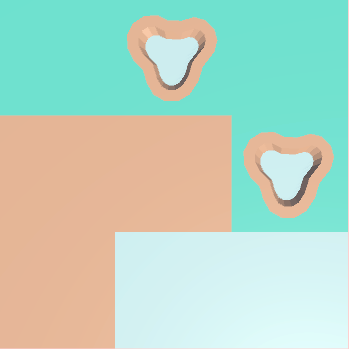
The input model is just dirt, water, puddles and grass.
The adjacency rules end up as such:
Grass and Puddles cannot go next to their own type
Water cannot go next to grass
With these, it should be very simple to see any rule breaks, the frequencies of the tiles mean that dirt is favoured the most which should be visible.

In the inspector, I can see the generated results of the editor and all the important values of the input model used. This is a rougher version which includes planning of future aspects not currently within the project. These aspects which I would like to improve upon include the pattern flipping option for tiles to be considered when rotated too. With this input model, a simple tiled method is currently used but I would like expansion to be an option in the future.
The editor generates 1 model currently, which may be quite limiting so it may be worth looking at combining multiple input models in the future. I can also check the generated frequencies and adjacency rules on the tiles' scriptable objects, if need be.
Below is my first correctly generated result using this input model, passed through correctly from the editor. Due to the constraints in place and the way the tiles are spawned in, it is not the most visually appealing. However with a basis in place, it should be easier to optimize and add onto now.


One slight caveat I noticed was that because of how simple the input model was and how shared the adjacency rules are, a lot of seeds end up with all of the grid having the same entropy value. This means it will currently start from the first tile in the grid when that happens, which can look quite obvious at times.
There were many mistakes before I reached a point where the algorithm was running as intended, which I'm planning to cover in the next post. These include issues with dividing by 0, infinite loops, and simple facepalming mistakes.


Comments